URL提取工具,类似JSFinder,更快更全更舒服
6.21更新
没权限去工具区发帖,只能发这里了。
使用JSFinder的的时候发现抓取到的url并不全,而且都不知道链接是不是活的,所以自己用golang写了个小工具。
工具原理很简单,测试比较少可能有些bug,欢迎大家测试反馈。
有什么建议可以提下,看看能不能更方便些。
对比图,随便找的一个后台,大家不要搞哦
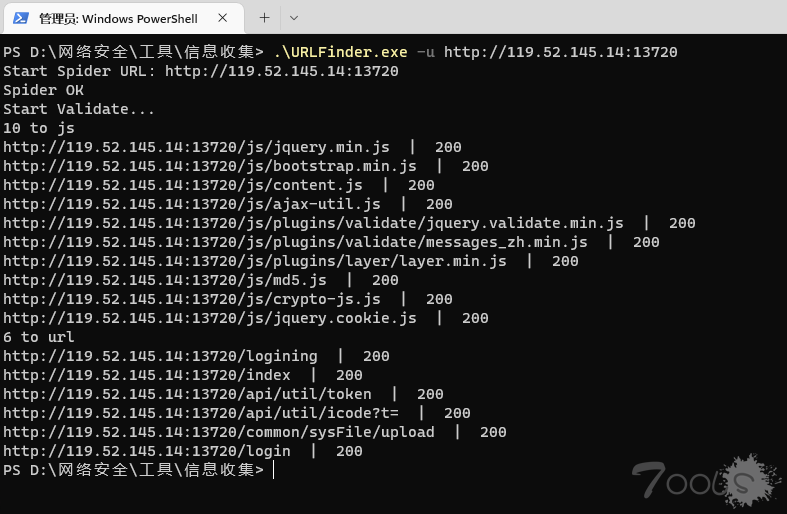
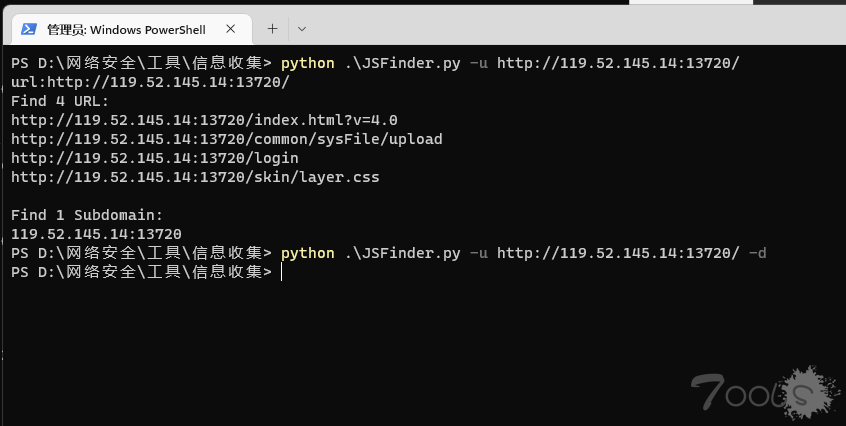
不知道为啥,JSFinder在一些网站 -d直接没返回
功能说明
1.抓取页面的URL链接(页面URL最多深入一层,防止抓偏)
2.抓取页面的JS链接
3.抓取JS中的URL链接
4.抓取到的链接会显示状态码 (带cookie操作时,可能会触发一些敏感功能,之后更新提供是否开启该功能,避免误操作)
5.支持抓取批量URL
6.支持结果导出到txt文件
结果会优先显示输入的域名,其他域名不做区分
结果会优先显示200,按从小到大排序(输入的域名最优先,就算是404也会排序在其他子域名的200前面)
使用:
URLFinder.exe -u http://xxx.xxx.com
URLFinder.exe -u http://xxx.xxx.com -m 2 -f url.txt -o
参数:
-u 目标URL
-a 自定义user-agent请求头
-m 模式: 1 正常抓取(默认), 2 深入抓取
-c 添加cookie
-f 批量url抓取
-o 结果导出到本地(会生成out文件夹)
参数:
-u 目标URL
-s 显示URL状态码与响应内容大小
-a 自定义user-agent请求头
-m 模式: 1 正常抓取(默认), 2 深入抓取
-c 添加cookie
-f 批量url抓取
-o 结果导出到本地(会生成out文件夹)
不要忽略404,被抓出来那就有它的道理(也可能是抓错了),404不代表这个url就没用,可能是少了一些参数呢
本帖不更新了,去github上下载新版本吧
2022/6/21
获取状态码从自动改为手动(-s)
添加显示响应内容大小
2022/6/16
优化提取规则增强兼容性
数组越界错误处理
2022/6/14
修复部分网站返回空值的问题
2022/6/13
1.添加自定义user-agent请求头功能
2.添加批量url抓取功能
3.添加结果导出功能
4.优化过滤规则
5.优化结果排版
2022/6/8
忽略ssl证书错误
源码上github了,可以自己编译,感谢各位的star
https://github.com/pingc0y/URLFinder
评论56次
没找webpack的测试,应该都是可以的
问下是用啥语言写的,如果用python通过字符串的注入在requests会不会获得更全点呢
能设置线程就更好了
支持我现在发现用go写程序的比python多了,是不是go更方便
兄弟,有一个chrome插件叫findsomething
感谢师傅的轮子
收藏了,跟JSFinder一起用
如果加个数据包得长度会更好
采纳了,下次更新加上
给你一个大大的star
如果加个数据包得长度会更好
为分享精神赞一个。需要朋友来拿。
下载了,给师傅点个star
用过还行吧,给师傅点个start了
感谢开源 不是很懂GO 看看先
感谢开源,可以学xi一波
有些网站需要ios或者安卓手机才能打开。xi望能添加个修改ua的功能。
归类看着不错 , 不知道对于 app.js内 抓 接口 会不会归类
感谢师傅的轮子,对于大批量的数据还是很方便的 支持批量域名会更方便
还得是github,需要可以自己编译
给师傅start了,试试怎么样