t00ls python 查域名与签到每日+2 tubi 脚本 (web端) (0414更新)
※写此脚本的目的为希望土司大佬们一起多赚些tubi 可以多发些悬赏帖或不吝于购买其他大佬开发的优秀脚本与程式 一同让土司更热闹繁荣※
签到部分代码与思路请查看 https://www.t00ls.com/thread-55689-1-1.html
查询域名思路为
官方登入api --> 取出 formhash 与 cookie
官方查看 tubi 记录api --> 判断今天有无完成查询域名任务
若今天没有查询过 至域名列表站点 --> 随机爬取一个域名 (原本有考虑3~5字母乱数英文域名+后坠 虽然少一个请求 不过域名短多人使用容易重复 域名长容易找到死域名)
然后post 查找域名页面 判断回传内容 若查过或不存在则重新找一个域名查询 查到有+tubi为止
成功运行图片
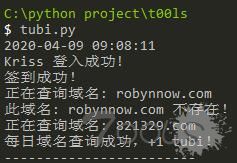
此程式 为 python 3 开发 本人Python版本为 Python 3.6.8
需要安装 requests 与 BeautifulSoup 库
若为自动每日执行 则还要安装 schedule
pip install requests
pip install BeautifulSoup4
pip install schedule
之后自行填入帐号与密码与安全提问问答 即可使用
查询域名代码如下
import requests
import urllib.request
import json
import re
from datetime import datetime
from time import sleep
import random
from bs4 import BeautifulSoup
uname = 'Kriss' #帐号
pswd = 'password' #密码MD5 32位(小)
qesnum = 0 # 安全提问 参考下面
qan = '' # 安全提问答案
# 0 = 没有安全提问
# 1 = 母亲的名字
# 2 = 爷爷的名字
# 3 = 父亲出生的城市
# 4 = 您其中一位老师的名字
# 5 = 您个人计算机的型号
# 6 = 您最喜欢的餐馆名称
# 7 = 驾驶执照的最后四位数字
def delhtml(html):
html=str(html)
dr = re.compile(r'<[^>]+>',re.S)
dd = dr.sub('',html)
return dd
def toarr(html):
a = delhtml(html)
a=a.split( )
return a
def randdm():
page = random.randrange(1,84)
url = 'https://www.yooym.com/mi.php?Page='+ str(page)
req = requests.get(url)
soup = BeautifulSoup(req.text,'lxml')
tra = soup.find_all("tr",class_="")
del tra[0]
rkey= random.randrange(0, len(tra))
randm = toarr(tra[rkey])[0]
return randm
def tslogin(uname,pswd,qesnum,qan):
logindata = {'action': 'login', 'username': uname, 'password': pswd, 'questionid': qesnum, 'answer': qan}
rlogin = requests.post('https://www.t00ls.com/login.json',data = logindata)
rlogj = json.loads(rlogin.text)
if (rlogj["status"]!="success"):
print ("登入失败,请检查输入资料是否正确!")
else:
print(uname,"登入成功!")
return rlogin
today = datetime.now()
print(today.strftime("%Y-%m-%d %H:%M:%S"))
rlogin = tslogin(uname,pswd,qesnum,qan)
if (rlogin != "") :
rlogj = json.loads(rlogin.text)
tscookie = requests.utils.dict_from_cookiejar(rlogin.cookies)
tbreq = requests.get('https://www.t00ls.com/members-tubilog.json',cookies=tscookie)
tblog = json.loads(tbreq.text)
loglen = len(tblog["loglist"])
allreason =""
for i in range(loglen):
logday = tblog["loglist"][i]["timeline"]
logdatetime = datetime.strptime(logday, "%Y-%m-%d %H:%M:%S")
logdatetime = logdatetime.strftime("%Y-%m-%d")
todaydate = today.strftime("%Y-%m-%d")
if (logdatetime == todaydate):
allreason += tblog["loglist"][i]["reason"]
else:
break
if ("查询新com域名" in allreason):
print("今天已经查询过域名了!")
else:
while True:
domainurl = randdm()
print ('正在查询域名:',domainurl)
querydomainsubmit = urllib.parse.quote("查询")
postdata = {'formhash': rlogj["formhash"], 'querydomainsubmit': querydomainsubmit, 'domain': domainurl}
rpost = requests.post('https://www.t00ls.com/domain.html',data = postdata,cookies=tscookie)
if ("域名查询可以积累域名的信息,为进一步了解做准备,不要为了TuBi而查询。" in rpost.text):
print ("每日域名查询成功,+1 tubi!")
break
elif("Error:查询出错!域名不存在或接口有误,返回为空!" in rpost.text):
print ("此域名:",domainurl,"不存在!")
else:
print ("此域名:",domainurl,"已查询过!")
sleep(1)
print ('------------------------')
下载压缩档内容为 自动签到+查找域名 2合一脚本 分为单次版以及每日版~
有拿去用的兄弟希望可以给个回复 让我知道可以正常使用 或是有任何错误欢迎私信我
---------------0413更新-------------------
此为旧版 若需要请购买0414更新版
---------------0414更新-------------------
tubi.py 43 行
tuby2.py 41 行
原本為
page = random.randrange(1,200)
改為
page = random.randrange(1,84)
不影响使用 不过原本会容易超出页数 导致只爬取第一页域名 时间久了容易重复
请已购买的大佬私信我拿新版 或是自行更新

评论51次
连着手动七八十天的我,也用上了自动签到,不得不说真香
这种脚本自动签到 会不会被官方打击啊 我在想这个问题 最近挺多这种自动签到脚本的
不用自动签到脚本,手动才是真爱。
连着手动一年的我,也用上了自动签到,不得不说真香
连着手动二百天的我,也用上了自动签到,不得不说真香
手动签到,不然都不一定想学xi
这域名被查询过的可真多。。。
我是靠自己手动签到也还行。
建议加入钉钉或者server酱的推送,签到完后能有个反馈
小伙,你会被关注的。哈哈。
佩服佩服!!!
我也准备弄弄自动签到
签到玩出新花样
已经xi惯手动签到,自动的总怕出问题漏了。。
插眼,域名脚本。师傅流批。
运行过后没有任何提示是什么情况啊?.gif)
谢谢大佬 ,分享
自动签到脚本越来越多,但不得不说真想
每天坚持手动签到,都成xi惯了。
无论是手签还是自动签都有用处,学xi了
我记得之前有个大佬分享过腾讯云函数配合自动签到的帖子,服务器都不用,真香。
吹雪表哥发的,我试了有几天会中断不知道怎么回事
虽然复制下来了但还是支持一下