SpiderX - JS前端加密自动化绕过工具
SpiderX - JS前端加密自动化绕过工具
前言:自行抽空写的爬虫工具,因为之前攻防遇到过一些前端加密的网页在内网,想爆破弱密码因为各种AES,DES的多层嵌套而无能为力,最近学习JS的过程中又想到爬虫模拟点击就可以绕过这种问题,但之前就有想法为什么很少有师傅写爬虫来模拟绕过js,所以就自己写了,同时为了方便新手使用我也制作了gui界面方便使用,同时我开源了代码,大家可以在check_login上自行修改来选择爆破检测的特征进行强化(因为作者不善gui美化的编写,AI对我的帮助很大~所以这方面AI痕迹比较明显,我并不避讳AI的使用,所以也没有刻意去除)。新人制作,请多多支持,以下效率的数据为AI评估,切勿较真。欢迎师傅们提修改意见,还有tools的发文markdown格式为什么没法用,我想从GitHub移植README.md过来发现不会正常显示....这里就写了点大概,详情看GitHub内容。
核心能力
▷ 红队渗透增强
◆ 行业痛点:突破前端传参加密年增35%的防御趋势(OWASP 2023数据)
◆ 爆破效率:自动化加密解析,速度达传统手工逆向方案的3-5倍
◆ 零基础操作:自动捕获JS加密函数,无需逆向工程经验
▷ 蓝队防御验证
◆ 漏洞检测:JS加密场景的弱密码检测效率提升620%
◆ 攻防推演:全链路模拟黑客攻击,精准验证WAF拦截策略
🕸SpiderX介绍内容已发布
🌊设置性能方面:
1.采用线程池而不是多线程来避免死锁而资源重复和卡死,通过对numbers的lock来保证顺序。
2.速度性能本地约可达到10次/s
3.支持验证码识别
4.支持多用户多密码的爆破开局配置自定义
千行代码,不过开箱即食用,为了美观交互性,所以为此制作了完整的gui界面来交互。
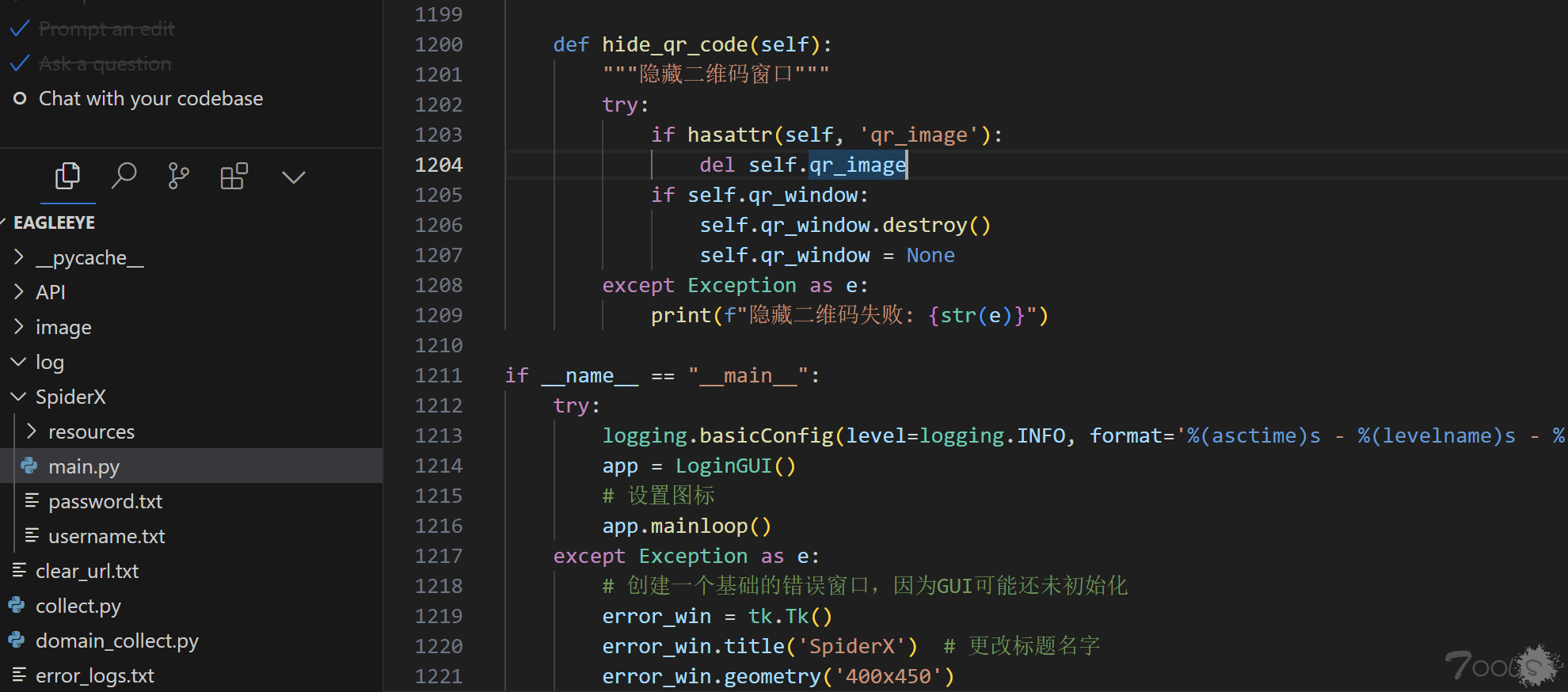
📖使用说明
1.先行下载本地网页服务的zip解压后运行app.py搭建web服务访问网页
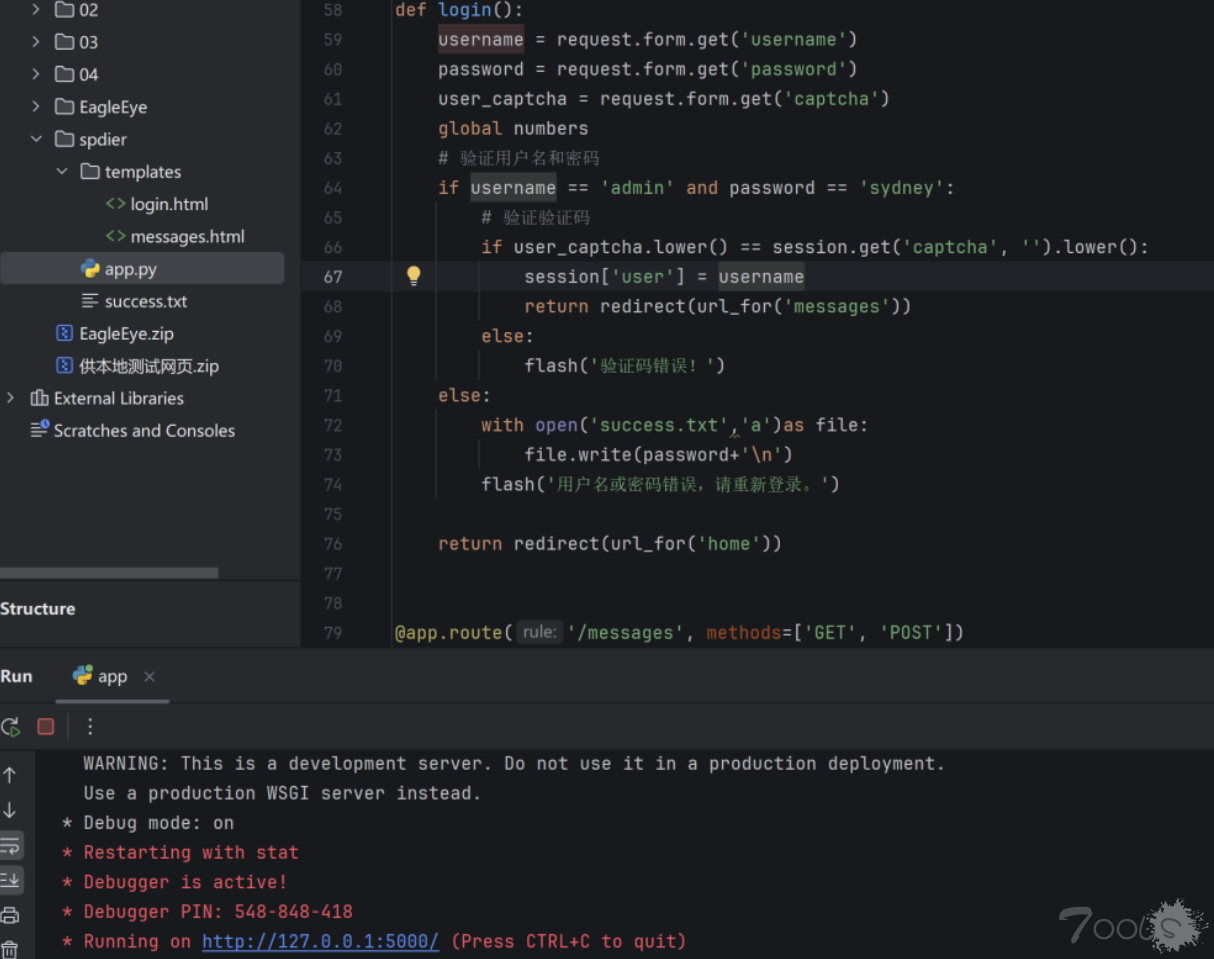
2.运行SpiderX工具的main.py
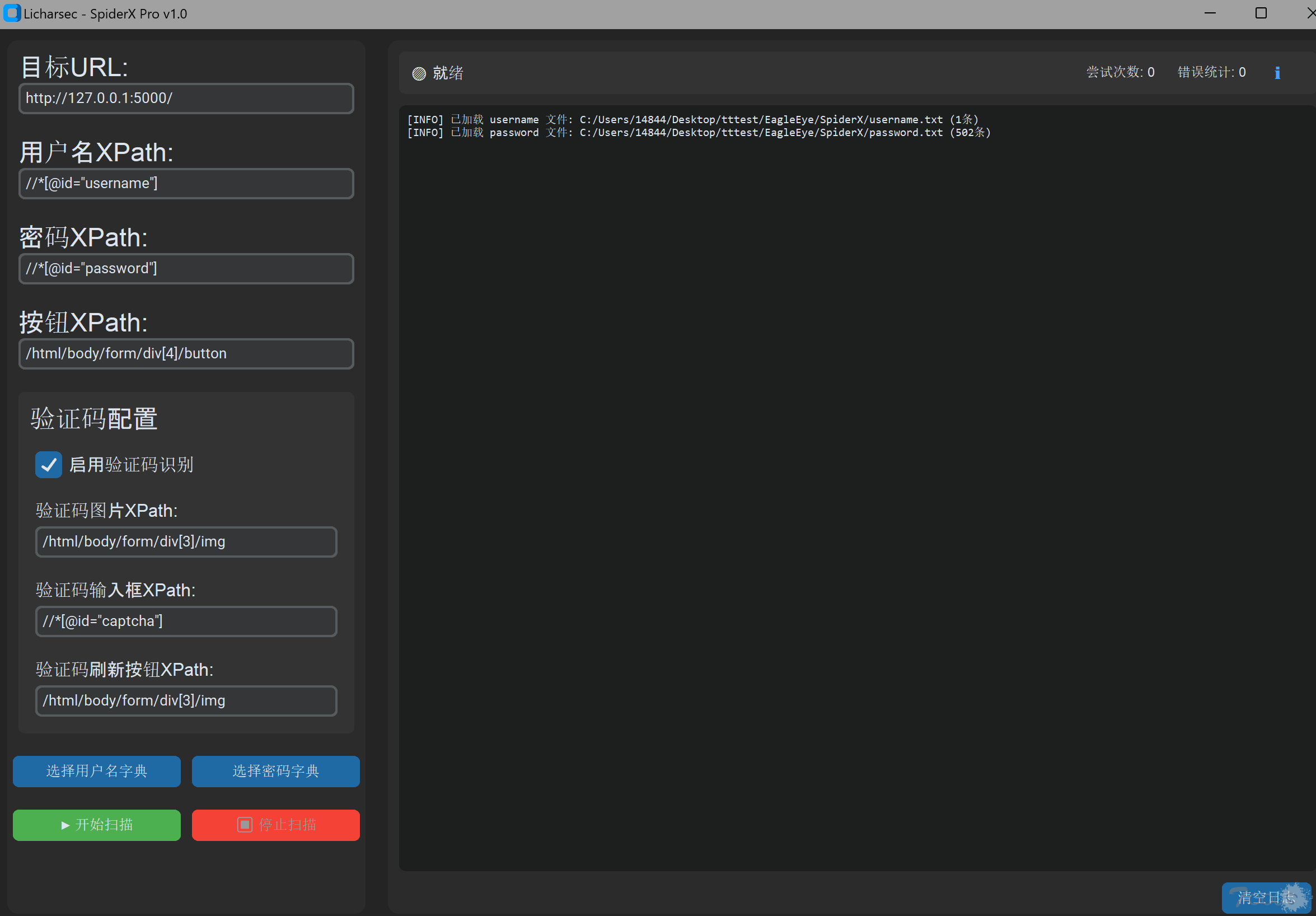
3.选择字典进行运行
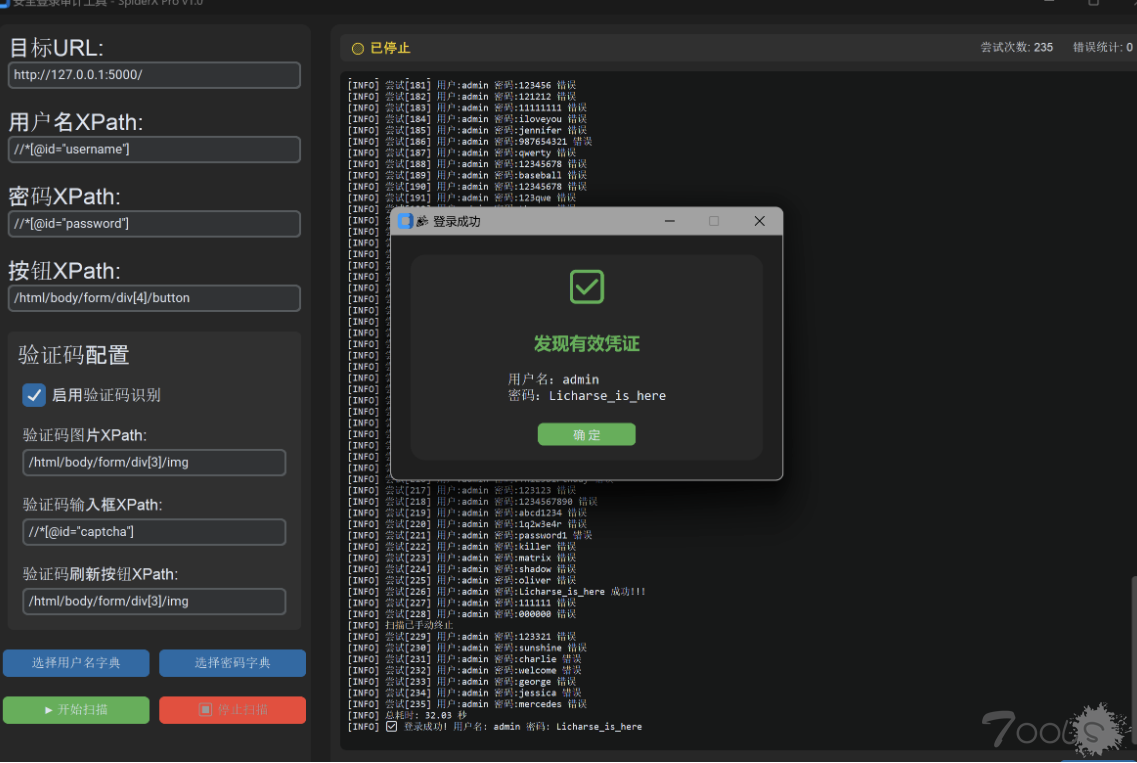
🧑💻作者留言:
爬虫模拟最大的问题就是反爬机制和各种报错,我尝试了很久也没办法完全处理各种的异常,因为有的异常selenium包里就没法绕过,所以就选择了最常见的几种格式来。同时为了有意向二开的师傅我也在GitHub上传了源码可以进行拉去分支使用,大家可以根据check_login函数来自己自定义反应成功机制,根据login函数来调整登陆的点击操作。
📶弊端说明:
因为没有什么经验写这类的工具,所以工具必然存在各种小弊端,欢迎师傅们提交建议供我调整,目前发现的问题有如下:
1.基本不存在丢包并发概率,有一般也是目标网站服务连接问题,但存在检测机制上因为内置chrome访问网页存在随机性的缓存问题会导致check_login的准确性不够,但调整超时时间又会降低效率,所以两者比较难以兼得,目前还在设法解决。
2.超大字典(大于四五千)的爆破疑似出现失真,建议字典爆破一次还是在千个数以内进行爆破。
结尾
https://github.com/LiChaser/SpiderX #GitHub工具地址
评论36次
https://github.com/gubeihc/blasting 这个和你这个差不多,虽然你用的是selenium,他用的其他的,但是有更方便的DrissionPage可以用
不错,研究一波
建议改成:绕过前端JS加密登陆爆破工具
selenium 太大了。
可以加个代理,代理到burp中
如果不是在登陆口,而是调用AES把某个数据包进行了加密,这种可以绕过麽
这种更偏向于爬虫的处理方式了,不过思路确实不错
测试很多确实有加密,绕过加密又费时,这个确实可以多一种绕过方法
这个真行 能省很多时间啊
老哥啊,运行代码报错[ERROR] 浏览器操作失败: module 'selenium.webdriver' has no attribute 'ChromeService'
我的也是这个思路,但是有个问题,就是有一些登录窗口是前端实现的,点击后弹出,貌似使用xpatch无法获取到登录框的情况
那个特定场景的alert可以用异常模块抛出来捕捉登录成功,最开始我试过但和常规的检测逻辑会冲突我就每加进去了,特定的场景还是要自己调试下
Windows java可以试一试 https://github.com/winezer0/CrackCaptchaLogin_Plus 需要自己打包一下
感谢大哥分享
我的也是这个思路,但是有个问题,就是有一些登录窗口是前端实现的,点击后弹出,貌似使用xpatch无法获取到登录框的情况
这个思路厉害,还没往过这方面想,github star送上
是个不错的思路啊 之前光想着看js解密了,没想到还能这么整
已食用,感谢分享👍
不错,学xi了
😄刚好用到,试一试,能绕过js加密省事很多
把mac下的兼容性做好一点。。。会很棒
https://github.com/gubeihc/blasting 这个和你这个差不多,虽然你用的是selenium,他用的其他的,但是有更方便的DrissionPage可以用
看了下确实不错,学到了,感谢感谢。这个作者的项目结构性也很好,有空研究学xi下。我这个可能就比较轻量化方便调试,还有师傅们有好的想法和见过类似的项目都可以告诉我,现在备考比较忙,空下来一定整理后重构下项目。