【Fofa会员的爬虫版工具】
0x01 场景
比如编写扫描器时,需要验证某个POC或者复现某个漏洞,但环境受限于企业版、不公开源码等原因无法搭建,目标漏洞在搜索引擎内又大部分已修复,这里搜索引擎使用Fofa,使用API获取会有大量冗余的问题,因为API获取的url貌似都是固定的,我获取多少数量的url,前面的都一样,导致我认为这些url存在漏洞的可能性较低,所以我需要搜索引擎靠后位置的一些目标URL来学习,可能靠后位置的url我验证100个就可以找到所需要的,而靠前位置的我需要验证1000个才能找到需要的
0x02 思路
- 1.加工自某位师傅(感谢)的脚本,忘记在哪看到的了 0.0! , 完善了一个bug,Fofa的某些搜索结果的url存在有小锁链和没有的情况(就是URL旁边点击后直接访问目标的小锁链),这时的标签是不同的,所以需要特别处理
- 2.获得URL是使用python的PyQuery模块加工网页源代码,获取标签内容
PyQuery模块用到的语法 from pyquery import PyQuery as pq #导入PyQuery模块 req = requests.get(url=url,headers=headers,cookies=cookies) doc=pq(req.text) #将获得的源代码进行标签化 doc('div.results_content .list_mod_t').items() #针对多个标签时,获得的标签集合在一起,后续获得标签内容为遍历集合后获得 relDoc('.ip-no-url').text() #针对1个标签时,获得标签的class为ip-no-url的标签内容 doc.find('a').eq(0).attr.href #查找标签下的a标签并获得href属性内容 - 3.获得总页数是使用正则提取的PyQuery处理过的标签内容(看到这的师傅,推荐去简单了解一下python的这个pq库或者那个beautifulsoup库,对以后获取自己需要的信息会有帮助,有思路的时候就会有想法嘛,对吧~)
pattern = re.compile(u'获得 (.*?) 条匹配结果') #使用(.*?)大法,强迫症师傅饶我一命~ result = re.findall(pattern,page) result = result[0].replace(',','') - 4.然后根据实际情况来输入从哪页开始,共获得多少页,最后加工一下交互就完成了,代码简单,能解决我的小需求就好 -.- 。
startPage = input("[+ 搜索结果共有{}页,请输入从第几页开始收集地址(例:5):".format(allPage)) page = input("[+ 搜索结果共有{}页,请输入准备收集页数(例:20):".format(allPage)) - 5.顺带说下Fofa开个普通会员蛮实用的(界面友好,交互友好),大不了就跟认识的朋友,同事,同学几个人或者这个帖子评论区找找有没有想买的一起买,毕竟账号没那么多登录限制的
0x03 使用
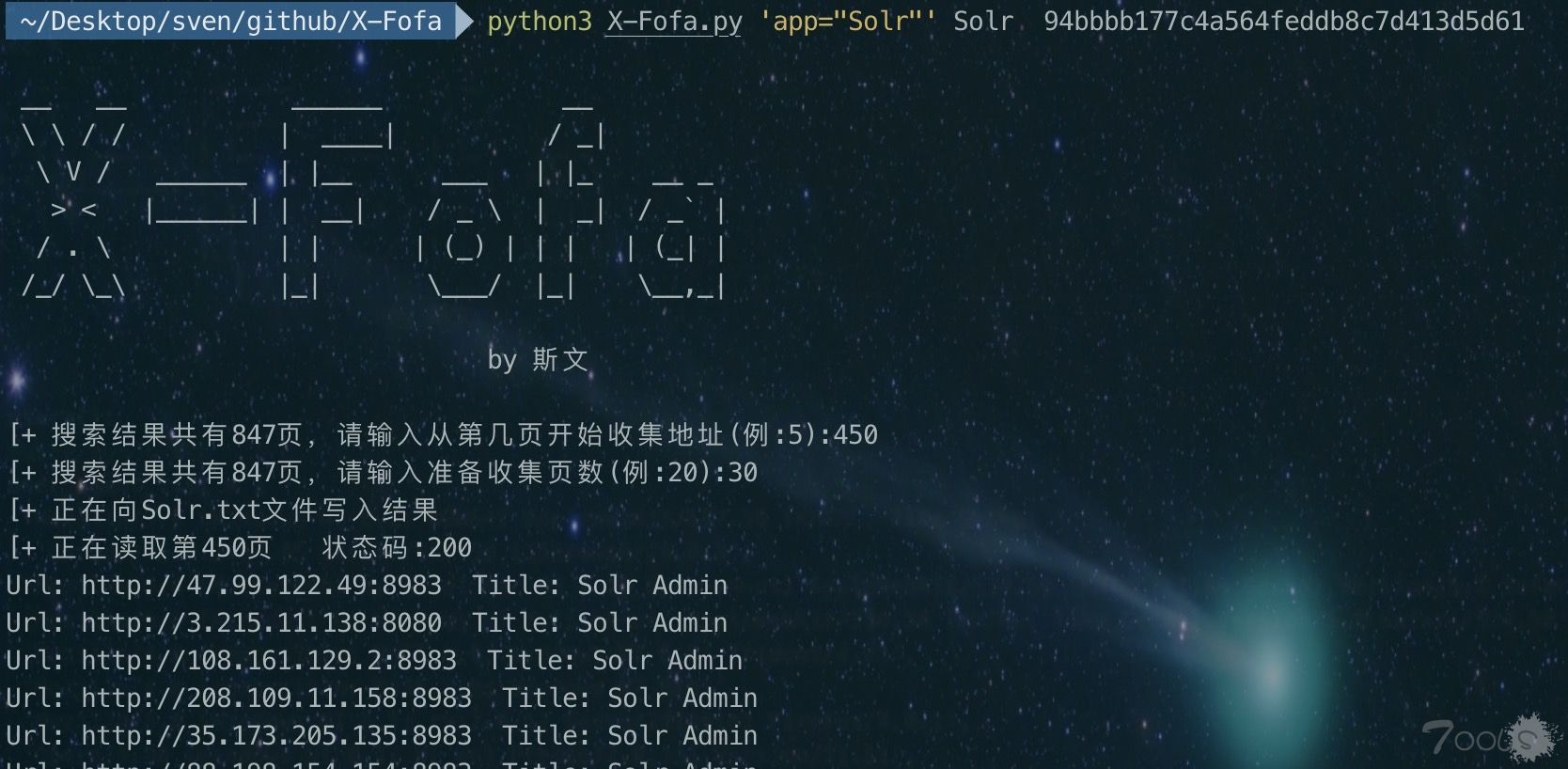
- Usage: python3 X-Fofa.py 'app="CouchDB"' CouchDB 94bbbb177c4a564feddb8c7d413d5d61
- Usage: python3 X-Fofa.py Fofa搜索语法 搜索结果文件名 Fofa的Cookie的_fofapro_ars_session值
- 按照需求输入 从哪页开始 和 获取多少页数 即可
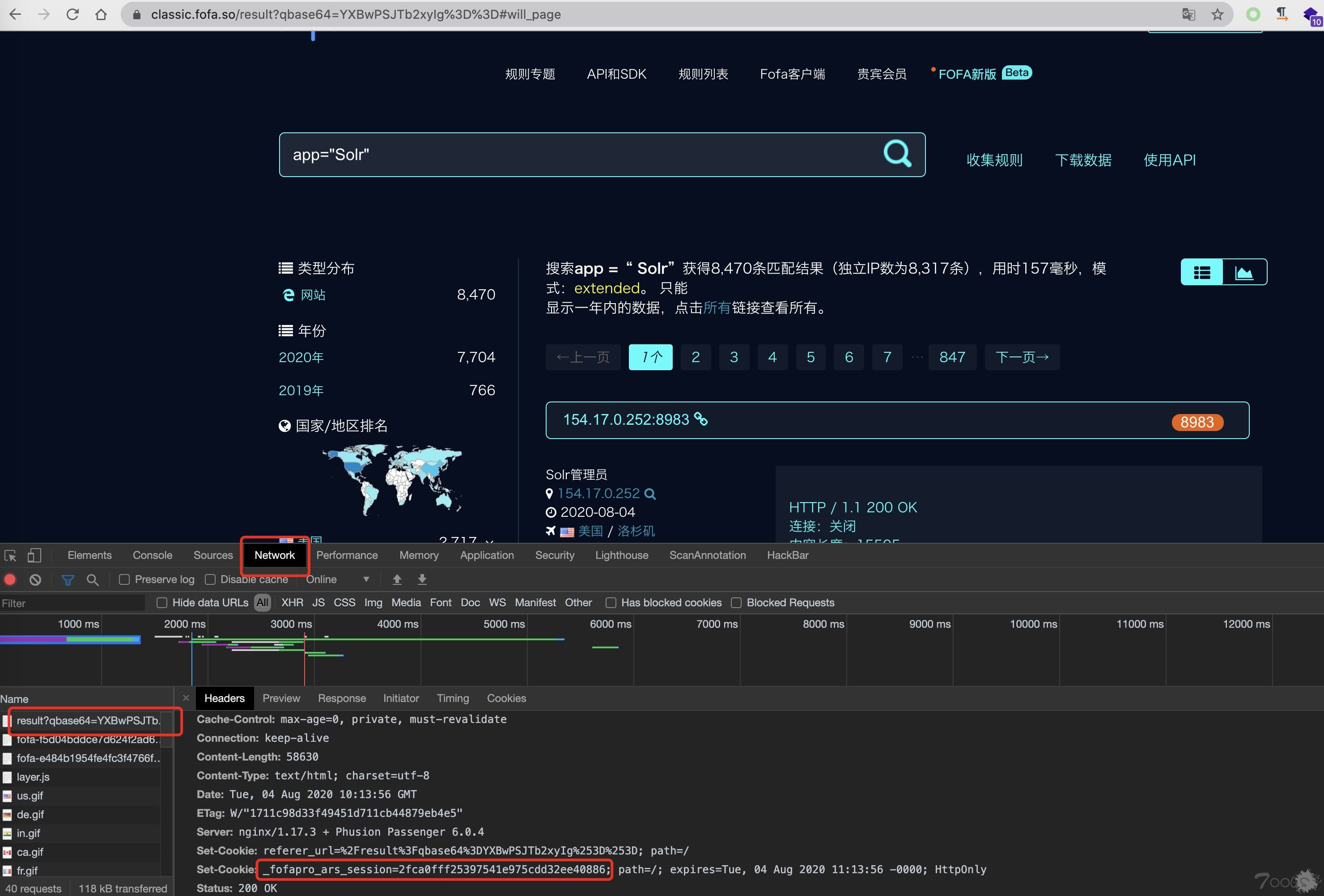
- 获得_fofapro_ars_session值
0x04 源码
#!/usr/bin/python3
import requests,time,random,os,re,sys,base64,urllib.parse
from pyquery import PyQuery as pq
banner = '''
__ __ ______ __
\ \ / / | ____| / _|
\ V / ______ | |__ ___ | |_ __ _
> < |______| | __| / _ \ | _| / _` |
/ . \ | | | (_) | | | | (_| |
/_/ \_\ |_| \___/ |_| \__,_|
by 斯文
'''
def usera():
#user_agent 集合
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
#随机选择一个
user_agent = random.choice(user_agent_list)
#传递给header
headers = { 'User-Agent': user_agent }
return headers
def getPage(cookie,search):
url='https://classic.fofa.so/result?page=1&qbase64={}'.format(search)
cookies = {'_fofapro_ars_session':cookie}
req = requests.get(url=url,headers=usera(),cookies=cookies)
pageHtml = pq(req.text)
page = (pageHtml('div.list_jg')).text()
# page = page.find('')
pattern = re.compile(u'获得 (.*?) 条匹配结果')
result = re.findall(pattern,page)
result = result[0].replace(',','')
if (int(result) % 10) >0:
allPage = int(result) // 10 + 1
else:
allPage = int(result) // 10
return allPage
def start(search,file,cookie):
search=search.encode(encoding="utf-8")
search=base64.b64encode(search).decode()
search=urllib.parse.quote(search)
# if os.path.exists("result.txt"): #删除存在的文件
# os.remove("result.txt")
# cookie = input("请输入Fofa的Cookie的_fofapro_ars_session值:")
allPage = getPage(cookie,search)
print(banner)
startPage = input("[+ 搜索结果共有{}页,请输入从第几页开始收集地址(例:5):".format(allPage))
page = input("[+ 搜索结果共有{}页,请输入准备收集页数(例:20):".format(allPage))
endPage = int(startPage) + int(page)
cookies={'_fofapro_ars_session':cookie}#这里是你的fofa账号登录后的cookie值
url='https://fofa.so/result?qbase64={}'.format(search)
# doc=pq(url)
print("[+ 正在向{}.txt文件写入结果".format(file))
with open('%s.txt'%file,'a+',encoding='utf-8') as f:
for i in range(int(startPage),endPage):
url='https://classic.fofa.so/result?page={}&qbase64={}'.format(i,search)
req = requests.get(url=url,headers=usera(),cookies=cookies)
if '游客使用高级语法' in req.text:
print('[- Cookie已失效,请重新填写https://classic.fofa.so的Cookie,不是https://fofa.so的Cookie')
break
print("[+ 正在读取第{}页 状态码:{}".format(i,req.status_code))
doc=pq(req.text)
url=doc('div.results_content .list_mod_t').items()
title=doc('div.list_mod_c ul').items()
for u,t in zip(url,title):
t.find('i').remove()
relUrl = u.find('a').eq(0).attr.href
relTitle = t.find('li').eq(0).text()
if 'result?qbase64=' in relUrl:
relDoc = pq(u)
relIp = relDoc('.ip-no-url').text()
relPort = (relDoc('.span')).find('a').eq(0).text()
relUrl = 'http://{}:{}'.format(str(relIp),relPort)
if relTitle == '':
relTitle = '空'
print("Url: %s Title: %s"%(relUrl, relTitle))
f.write("%s\n"%(relUrl))
f.flush()
time.sleep(3)
if __name__ == '__main__':
if len(sys.argv)==1:
print(banner)
print('''Usage:请输入参数\n例如:python X-Fofa.py 'app="Solr"' Solr 94bbbb177c4a564feddb8c7d413d5d61\n例如:python FofaCrawler.py 'app="Solr"'(Fofa搜索语法) Solr(搜索结果文件名) 94bbbb177c4a564feddb8c7d413d5d61(Fofa的Cookie的_fofapro_ars_session值)''')
sys.exit(0)
search=sys.argv[1]
file=sys.argv[2]
cookie = sys.argv[3]
start(search,file,cookie)
评论13次
来个GUI版本,可导出CSV
这玩意儿公开啥啊,fofa团队看到的话,又加反爬机制,自己写个py简单的一笔
场景不同,我是为了维护扫描器POC用的0.0
雷石不是发过ui界面嘛 师傅
好用是好用,就是买不起会员~~哎
一开始还以为会员账号已经在里面了,再仔细看下才发现原来还是要自己提供会话cookie.......
师傅别光喝酒,吃点花生米,哈哈
一开始还以为会员账号已经在里面了,再仔细看下才发现原来还是要自己提供会话cookie.......
来个GUI版本,可导出CSV
fofa客户端直接搜索导出不能满足么
用api可以一个会员多个人用哈哈哈
[+ 搜索结果共有849页,请输入从第几页开始收集地址(例:5):6[+ 搜索结果共有849页,请输入准备收集页数(例:20):2[+ 正在向Solr.txt文件写入结果[+ 正在读取第6页 状态码:200[+ 正在读取第7页 状态码:200会员cookie,但是没有爬到内容 ==
不是吧不是吧,你的cookie会不会不是这个网站的cookie吧 https://classic.fofa.so,选的https://fofa.so/可不行哦
啊..尴尬..没注意是https://classic.fofa.so的cookie
[+ 搜索结果共有849页,请输入从第几页开始收集地址(例:5):6[+ 搜索结果共有849页,请输入准备收集页数(例:20):2[+ 正在向Solr.txt文件写入结果[+ 正在读取第6页 状态码:200[+ 正在读取第7页 状态码:200会员cookie,但是没有爬到内容 ==
不是吧不是吧,你的cookie会不会不是这个网站的cookie吧 https://classic.fofa.so ,选的https://fofa.so/可不行哦
fofa客户端直接搜索导出不能满足么
[+ 搜索结果共有849页,请输入从第几页开始收集地址(例:5):6 [+ 搜索结果共有849页,请输入准备收集页数(例:20):2 [+ 正在向Solr.txt文件写入结果 [+ 正在读取第6页 状态码:200 [+ 正在读取第7页 状态码:200 会员cookie,但是没有爬到内容 ==
可以可以....