零基础人工智能-第一篇Tensoflow2.0 入门
Tensoflow2.0 入门
1.什么是人工智能
2.Tensorflow2.0安装
2.1 环境准备
2.2 TF2.0 CPU版本安装
2.3 安装jupyter notebook
2.4 测试
一 、什么是人工智能
了解Tensoflow2.0首先需要简单介绍人工智能机器学习和深度学习,可以简单打个比方一个小年轻打算做大老板,很多人认为这是一个不切实际的想法,很长时间被认为是An Idiot 蠢蛋,过了一段时间人们发现小伙的才能学习。
蠢蛋都会学习,老板不是梦想,就像只教一个蠢蛋下围棋,只用4年,蠢蛋就战胜了师傅,又过了3年蠢蛋甚至打爆了世界冠军,蠢蛋如何学习那?
以做数学题为例,看题先审题,审题完找可用信息,将可用信息的数字,关键类型,可能题型找到,与记忆中同类型题对比,识别新题,推理答案,甚至预测出题人下次出什么题,这里面找可用信息,将可用信息关键找到,再将信息与记忆对比,这部分对于做题准确度十分关键,也就有了很多方法,对照书本死板硬套等,麻烦都要对照都要单线程推,这时,好学生提建议用脑子,层层迭代,方向神经元激活,机器学习类比例蠢蛋学习,用脑学生可以类比深度学习,这里说的数学题本指的是视觉感知,大体过程是低层感知(low-level sensing) 预处理(pre-processing) 特征提取(feature extract) 特征选择(feature selection) 推理(inference) 预测(prediction) 识别(recongnition),预处理,特征提取,特征选择概括叫特征表达,特征表达对算法的准确性起到决定性作用,这一部分靠人工提取特征的方法很多,但麻烦,特征量多如早期图像识别要在图像打标,打tag,自然语言处理找一段文字属性。
深度学习框架其实是基于深度学习的训练框架主要实现对海量数据的读取、处理及训练,主要部署在 CPU 及 GPU 服务集群,主要侧重于海量训练模型实现、系统稳定性及多硬件并行计算优化等方面的任务。目前主流的深度学习训练软件框架主要有 TensorFlow,MXNet,Caffe/2+PyTorch 等。
TF以其功能全面,兼容性广泛和生态完备而著称。框架允许在任何CPU或GPU上运行且支持移动或服务器设备。该软件框架由谷歌大脑(Google Brain)团队主要支撑,实现了多 GPU 上运行深度学习模型的功能,可以提供数据流水线的使用程序,并具有模型检查,可视化和序列化的配套模块。且其生态系统已经成为深度学习开源软件框架最大的活跃社区。
二 、Tensorflow2.0安装
2.1 环境准备
在Windows10上面,使用conda管理的python环境,通过conda安装cuda与cudnn(GPU支持),通过pip安装的tensorflow2.0。经过尝试只是最简单的安装方式,无需配置复杂环境。conda是很好用python管理工具,可以方便建立管理多个python环境。推荐使用安装miniconda,大家可以理解为精简版的anaconda,
miniconda推荐使用清华源下载:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
windows推荐地址:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-4.7.10-Windows-x86_64.exe
2.2 TF2.0 CPU版本安装
TF CPU安装比较简单,因为不需要配置GPU,所以windows ubuntu macOS安装方式都类似,缺点就是运行速度慢,但是用于日常学习使用还是可以的。
Windows情况下:
新建TF2.0 CPU环境(使用conda 新建环境指令 python==3.6表示新建了一个python3.6环境)
conda create -n TF_2C python=3.6完成后就可以进入此环境
进入TF_2C环境
conda activate TF_2C
进入后我们就可以发现:(TF_2C)在之前路径前面,表示进入了这个环境。使用conda deactivate可以退出。
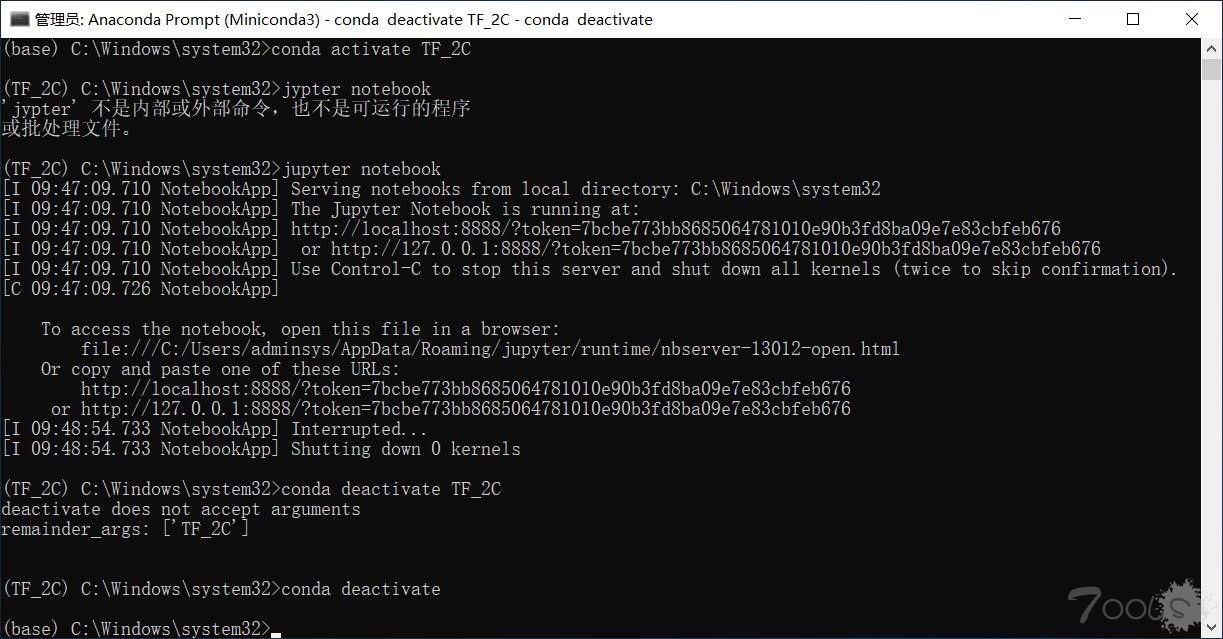
安装TF2.0 CPU版本(后面的 -i 表示从国内清华源下载,速度比默认源快很多)
pip install tensorflow==2.0.0 -ihttps://pypi.tuna.tsinghua.edu.cn/simplepip install jupyterjupyter notebook
如上图会打开浏览器界面,项目文件默认会在c盘配置,可以直接跳过配置,尝试运行环境或配置jupyter,需要修改很多路径,比较麻烦。
jupyter notebook --generate-config

打开“C:\Users\Administrator\.jupyter”文件夹,可以看到里面有个配置文件。
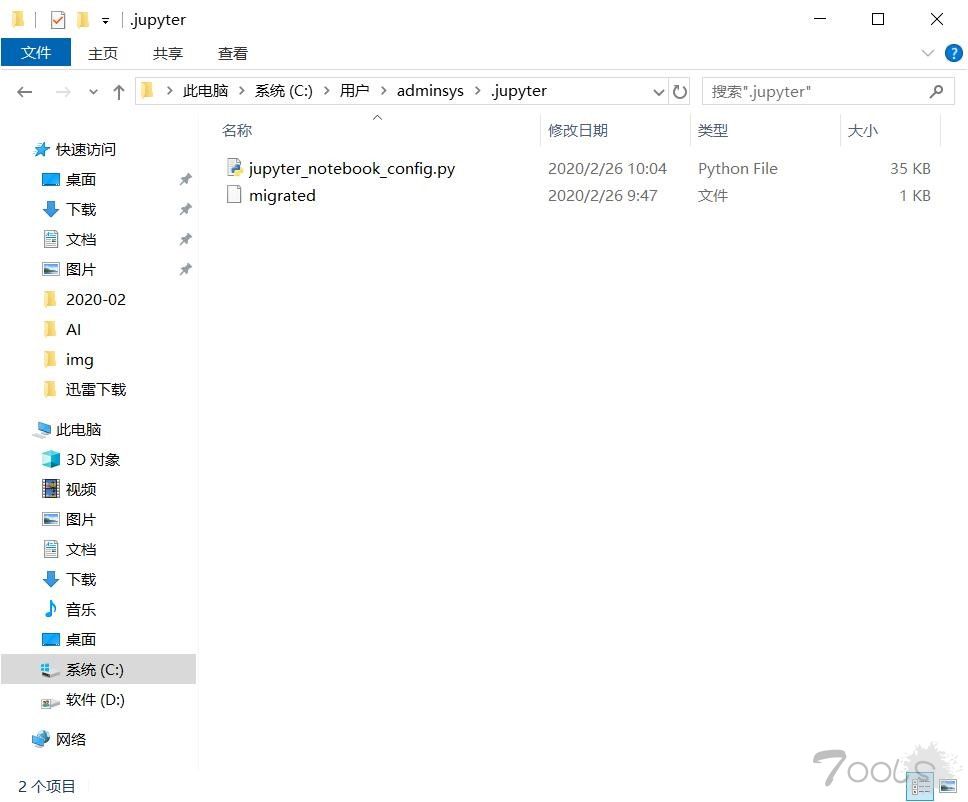
修改jupyter_notebook_config.py配置文件
打开这个配置文件,找到“c.NotebookApp.notebook_dir=”,把路径改成自己的工作目录。
配置文件修改完成后, 以后在 jupyter notebook 中写的代码等都会保存在自己创建的目录中。
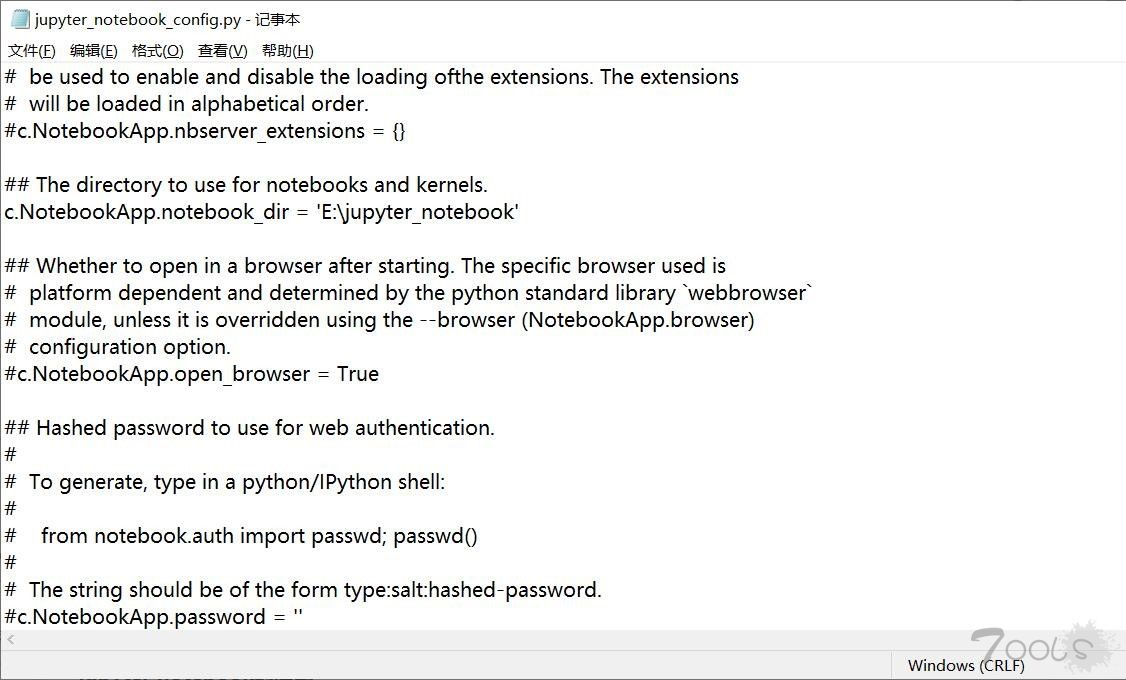
配置文件修改完成后, 以后在 jupyter notebook 中写的代码等都会保存在自己创建的目录中。再启动jupyter。
2.4 测试
在jupyter notebook右边new一个新的python3项目运行测试代码,随机产生训练和验证数据,通过构建的神经网络模型进行训练测试(程序本身没有实际意义,仅为验证环境安装正确)
mport numpy as np
import tensorflow as tf
from tensorflow.keras import layers
print(tf.__version__)
print(tf.keras.__version__)
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
train_x = np.random.random((1000, 72))
train_y = np.random.random((1000, 10))
val_x = np.random.random((200, 72))
val_y = np.random.random((200, 10))
dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y))
dataset = dataset.batch(32)
dataset = dataset.repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_x, val_y))
val_dataset = val_dataset.batch(32)
val_dataset = val_dataset.repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset, validation_steps=3)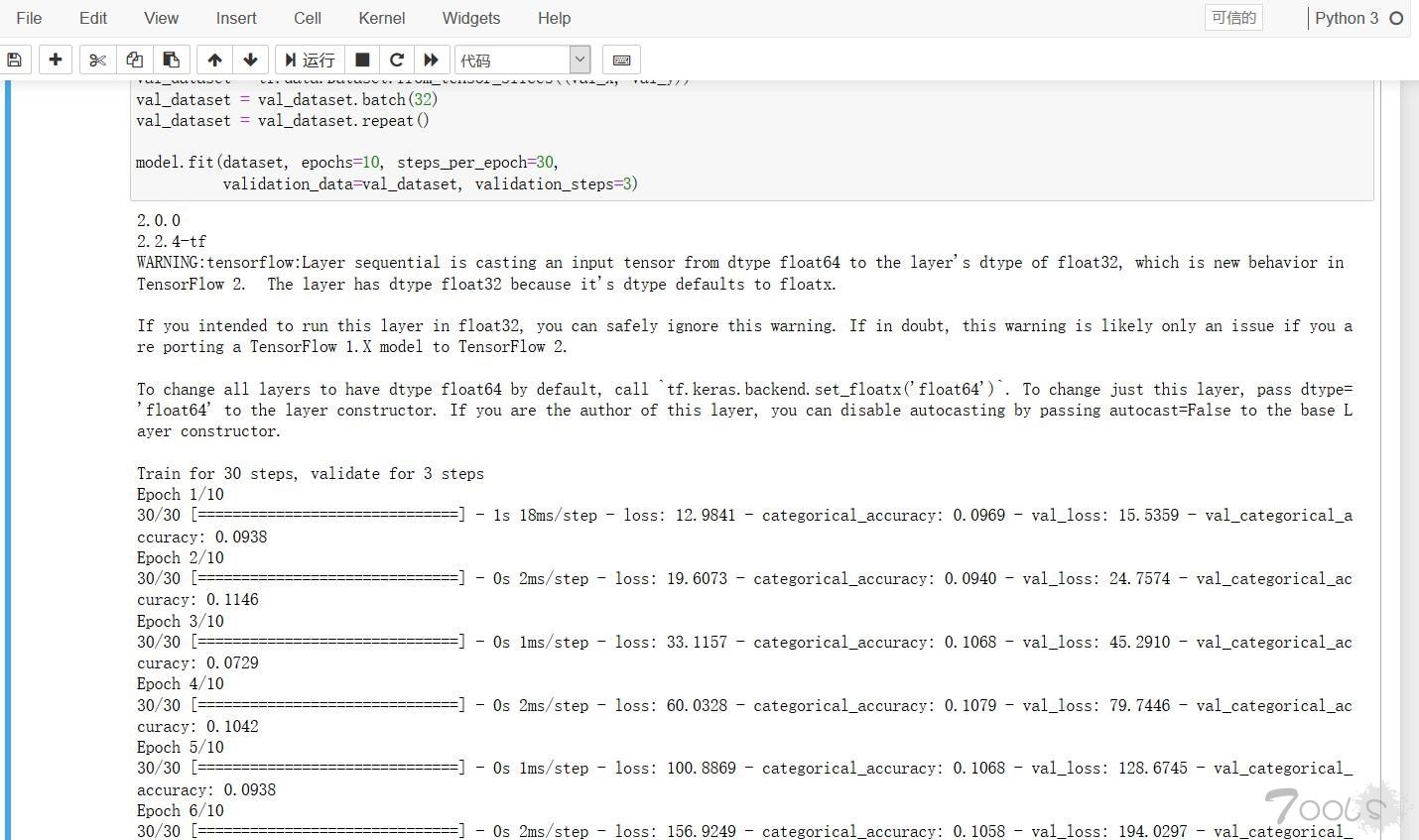
这是层堆叠Sequential模型,整个过程分为5步:
1.创建Sequential模型;
2.添加所需要的神经层;
3.使用.compile方法确定模型训练结构;
4.使用.fit方法使模型与训练数据“拟合”;
5.predict方法进行预测。
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
然后用Softmax函数来处理分类问题从而计算类的概率。
构建好模型后,通过调用 compile 方法配置该模型的学习流程:
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])loss:损失函数,通常把模型关于单个样本预测值与真实值的差称为损失,损失越小,模型越好,而用于计算损失的函数称为损失函数。通常“引导“模型朝正确方向优化。
metrics:评价函数,指标,分类正确的比例,用于评估当前训练模型的性能。
然后使用.fit方法进行测试数据与模型的拟合
dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y))
dataset = dataset.batch(32)
dataset = dataset.repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_x, val_y))
val_dataset = val_dataset.batch(32)
val_dataset = val_dataset.repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset, validation_steps=3)
看到如图一个简单的模型就训练好了。
这或许不会再是我写无关安全的第一篇文章,在我看来安全和黑客更像是迟暮的球星,却依旧倔强的在球场上奔跑 ;在恶意的碰撞犯规践踏中支撑不倒,在高大身影堆积起来的waf中穿行,就像他们在人生路上行走的态度一样如出一辙.
命,是弱者的借口, 运,是强者的坚词。
王者犹在 传奇不朽。---李治霖
自评TCV:5
评论19次
xi列文章贵在坚持,建议楼主整个目录归档,每篇都更新下目录,方便后面的人查阅。
小建议哈,长期更新的话建议从基础算法开始讲解吧,大多数人可能连K临近是啥都不知道呢,直接开始Ts写代码可能看不太懂。
建议出一些人工智能数学基础类的科普文章~
学完之后能识别验证码嘛?
学完直接起飞~
期待后续内容
之前学xi过一点点,梯度下降法 奈何数学太差看不懂
这个第一课应该先来点概率论、线性代数和微积分。。。
人工智能给安全一个新的方向,不过目前还有很多需要人工来操作,毕竟人工智能还有些不完美的地方。安全的分支太多,每天在各种新信息和新技术中,有一种顾此失彼的感觉,基础不好,很难跟上各种技术潮流。
安全在人工智能上的应用基本在吹的阶段。
搞普通研究不需要。
在我看来安全和黑客更像是迟暮的球星,却依旧倔强的在球场上奔跑 。楼主为什么发出如此感叹呢?安全在人工智能方向上不是大有作为吗?
玩这个GPU是一定要的。。
期待连载!
学完之后能识别验证码嘛?
期待连载,学xi新技术
之前就简单入门过, 后续就不会了
这方面没怎么去了解,确实看着吃力
谢谢lz,写得很清楚,仔细对着代码一行一行看下来就清楚了
小建议哈,长期更新的话建议从基础算法开始讲解吧,大多数人可能连K临近是啥都不知道呢,直接开始Ts写代码可能看不太懂。
xi列文章贵在坚持,建议楼主整个目录归档,每篇都更新下目录,方便后面的人查阅。